Dynamic facial expression recognition based on spatial key-points optimized region feature fusion and temporal self-attention
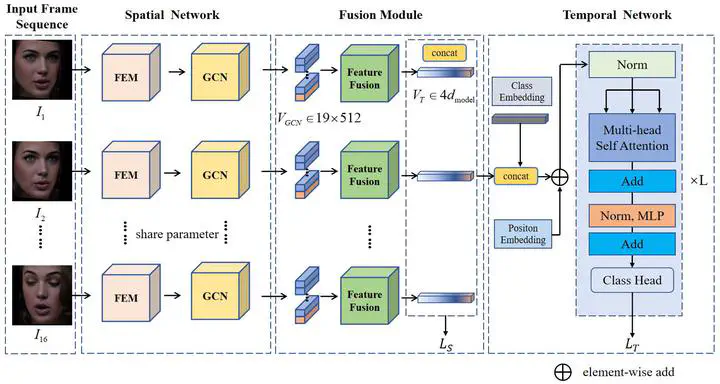 Image credit: Elsevier
Image credit: ElsevierAbstract
Dynamic facial expression recognition (DFER) is of great significance in promoting empathetic machines and metaverse technology. However, dynamic facial expression recognition (DFER) in the wild remains a challenging task, often constrained by complex lighting changes, frequent key-points occlusion, uncertain emotional peaks and severe imbalanced dataset categories. To tackle these problems, this paper presents a depth neural network model based on spatial key-points optimized region feature fusion and temporal self-attention. The method includes three parts: spatial feature extraction module, temporal feature extraction module and region feature fusion module. The intra-frame spatial feature extraction module is composed of the key-points graph convolution network (GCN) and a convolution network (CNN) branch to obtain the global and local feature vectors. The newly proposed region fusion strategy based on face spatial structure is used to obtain the spatial fusion feature of each frame. The inter-frame temporal feature extraction module uses multi-head self-attention model to obtain the temporal information of inter-frames. The experimental results show that our method achieves accuracy of 68.73%, 55.00%, 47.80%, and 47.44% on the DFEW, AFEW, FERV39k, and MAFW datasets. Ablation experiments showed that the GCN module, fusion module, and temporal module improved the accuracy on DFEW by 0.68%, 1.66%, and 3.25%, respectively. The method also achieves competitive results in terms of parameter quantity and inference speed, which demonstrates the effectiveness of the proposed method.
Zhiwei Huang 黄志伟
Master. The main contributor of this website.
A master student of this laboratory, research interests include Artificial Intelligence, Facial Expression recognition and System Design.
Yu Zhu 朱煜
Professor. Experts in artificial intelligence and computer vision. Lab leader.
Leader of this laboratory, research interests include Artificial Intelligence, Computer Vision, Industrial controls, Digital Image and Video Processing, Machine learning, Deep Learning and Applications.
Hangyu Li 李航宇
PhD. Super listener of 《三国恋》🎵.
A doctoral student of this laboratory, research interests include Neural Radiance Fields, Medical Image Processing and Generative Model.