Dual attention transformer with adaptive frequency enhancement for real-world Chinese–English scene text image super-resolution
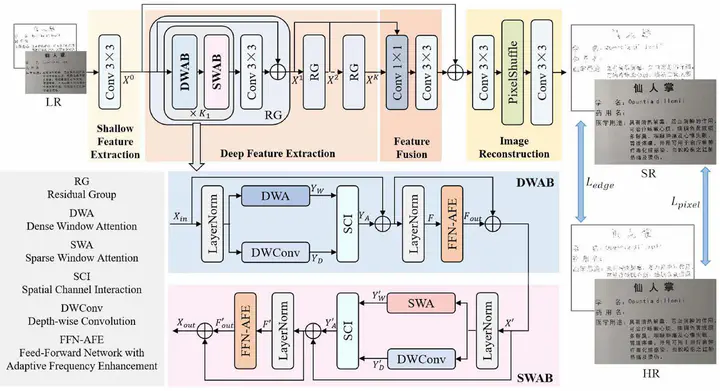 Image credit: Multimedia Systems
Image credit: Multimedia SystemsAbstract
Scene text image super-resolution (STISR) has achieved remarkable performance on the pure English dataset, TextZoom. Nevertheless, existing STISR models are primarily designed for fixed-size English text images, limiting their ability to reconstruct structurally complex characters like Chinese characters. Due to the squared computational complexity of standard self-attention, existing methods usually restrict the self-attention calculation within local windows, leading to a limited receptive field. In this paper, we propose a dual attention transformer with adaptive frequency enhancement (DA2FE) model which alternates between two complementary window attention mechanisms. Specifically, dense window attention (DWA) facilitates interactions between neighboring tokens, which is beneficial for learning local features. Sparse window attention (SWA) establishes associations between spaced tokens, enabling effective global information extraction. Additionally, we incorporate a parallel depth-wise convolution (DWConv) branch to establish cross-window relations. Subsequently, a spatial-channel interaction module is employed to facilitate the bi-directional interaction between the window attention branch and the DWConv branch. Furthermore, we design a feed-forward network with adaptive frequency enhancement (FFN-AFE), which introduces a learnable quantitative matrix in the frequency domain to adaptively select and enhance significant frequency information. Finally, the output features from multiple layers are aggregated and refined to provide more comprehensive information for SR reconstruction. Comparative experiments with advanced methods on the Real-CE dataset demonstrate our superior performance in terms of objective indicators and subjective visual results for both 2× and 4× STISR tasks. Furthermore, DA2FE exhibits excellent results on natural image super-resolution datasets, further demonstrating its broad applicability.
Yanbin Liu 刘燕滨
Master.
A master student of this laboratory, research interests include Computer Vision, Text Image Analysis and Super-resolution Reconstruction.
Qin Shi 施秦
Master.
A master student of this laboratory, research interests include Artificial Intelligence, Text Image Processing and Image Super-resolution.
Ziming Zhu 朱梓铭
PhD. Loyal listener of Jay Chou.
A doctoral student of this laboratory, research interests include Artificial Intelligence, Autonomous Driving Environment Perception, 3D Object Detection and Semantic Occupancy Prediction.
Yu Zhu 朱煜
Professor. Experts in artificial intelligence and computer vision. Lab leader.
Leader of this laboratory, research interests include Artificial Intelligence, Computer Vision, Industrial controls, Digital Image and Video Processing, Machine learning, Deep Learning and Applications.