CSV-Occ: Fusing Multi-frame Alignment for Occupancy Prediction with Temporal Cross State Space Model and Central Voting Mechanism
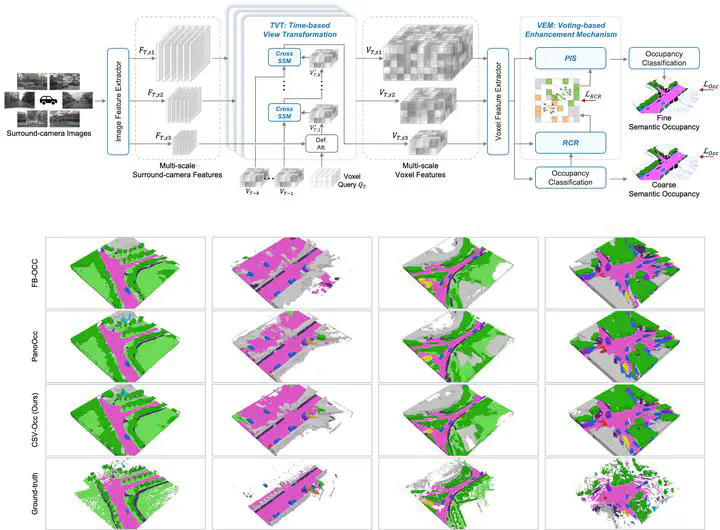 Image credit: ICML
Image credit: ICMLAbstract
Recently, image-based 3D semantic occupancy prediction has become a hot topic in 3D scene understanding for autonomous driving. Compared with the bounding box form of 3D object detection, the ability to describe the fine-grained contours of any obstacles in the scene is the key insight of voxel occupancy representation, which facilitates subsequent tasks of autonomous driving. In this work, we propose CSV-Occ to address the following two challenges: (1) Existing methods fuse temporal information based on the attention mechanism, but are limited by high complexity. We extend the state space model to support multi-input sequence interaction and conduct temporal modeling in a cascaded architecture, thereby reducing the computational complexity from quadratic to linear. (2) Existing methods are limited by semantic ambiguity, resulting in the centers of foreground objects often being predicted as empty voxels. We enable the model to explicitly vote for the instance center to which the voxels belong and spontaneously learn to utilize the other voxel features of the same instance to update the semantics of the internal vacancies of the objects from coarse to fine. Experiments on the Occ3D-nuScenes dataset show that our method achieves state-of-the-art in camera-based 3D semantic occupancy prediction and also performs well on lidar point cloud semantic segmentation on the nuScenes dataset. Therefore, we believe that CSV-Occ is beneficial to the community and industry of autonomous vehicles.
Ziming Zhu 朱梓铭
PhD. Loyal listener of Jay Chou.
A doctoral student of this laboratory, research interests include Artificial Intelligence, Autonomous Driving Environment Perception, 3D Object Detection and Semantic Occupancy Prediction.
Yu Zhu 朱煜
Professor. Experts in artificial intelligence and computer vision. Lab leader.
Leader of this laboratory, research interests include Artificial Intelligence, Computer Vision, Industrial controls, Digital Image and Video Processing, Machine learning, Deep Learning and Applications.
Jiahao Chen 陈加昊
Master.
A master student of this laboratory, research interests include 3D Object Detection, Point Cloud Processing and 4D Millimeter Wave Radar.