Occluded person re-identification based on parallel triplet augmentation and parameter-free token spatial attention
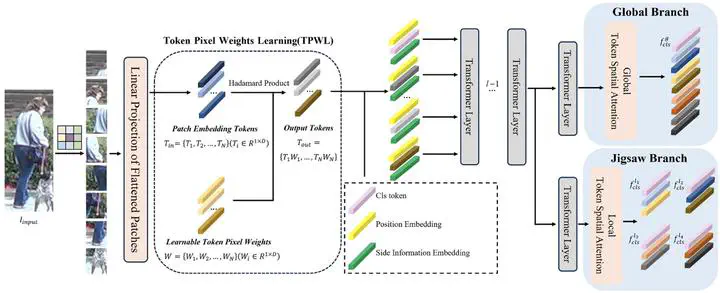 Image credit: Springer
Image credit: SpringerAbstract
The task of occluded person Re-identification(Re-ID) is challenging because only local information can be used to make judgments. Also, occlusion may not be present in the training samples, leading to limited performance of the model in inference. Traditional data augmentation schemes that resize, flip, and erase the input image can alleviate this problem, but the serial approach still results in unbalanced samples. To overcome this problem, we propose Parallel Triplet Augmentation (PTA), which involves applying three different data augmentation schemes to a single image during the training phase, thereby robustly expanding the training data. At the same time, non-occluded critical regions of an image tend to provide more discriminative features, so Vision Transformer-based models that process images in chunks show significant advantages. Based on this, we design a parameter-free Token Spatial Attention (TSA) mechanism. TSA uses different schemes for different branches to calculate the weights of each image patch, and then fuses the information in all the patch embedding tokens with the classification head token, thus increasing the amount of spatial information in the classification head token. Using TransReID as a backbone, the experimental results on two occluded datasets (Occluded-Duke and Occluded-ReID) indicate that the proposed method is competitive compared to state-of-the-art methods, with a rank-1 accuracy 0.7% higher on Occluded-Duke. On two non-occluded datasets (Market-1501 and DukeMTMC-ReID) and one vehicle dataset (VeRi-776), the proposed method has also reached state-of-the-art methods, with a rank-1 accuracy 0.3% higher on the VeRi-776 dataset.
Hangyu Li 李航宇
PhD. Super listener of 《三国恋》🎵.
A doctoral student of this laboratory, research interests include Neural Radiance Fields, Medical Image Processing and Generative Model.
Yu Zhu 朱煜
Professor. Experts in artificial intelligence and computer vision. Lab leader.
Leader of this laboratory, research interests include Artificial Intelligence, Computer Vision, Industrial controls, Digital Image and Video Processing, Machine learning, Deep Learning and Applications.
Shengze Wang 王圣泽
Master.
A Master student of this laboratory, research interests include Computer Vision, Deep Learning and Person Re-identification (ReID).
Ziming Zhu 朱梓铭
PhD. Loyal listener of Jay Chou.
A doctoral student of this laboratory, research interests include Artificial Intelligence, Autonomous Driving Environment Perception, 3D Object Detection and Semantic Occupancy Prediction.