TransMRE: Multiple Observation Planes Representation Encoding With Fully Sparse Voxel Transformers for 3-D Object Detection
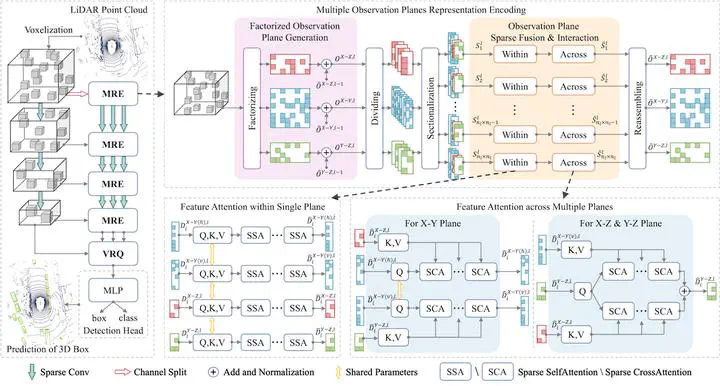 Image credit: IEEE
Image credit: IEEEAbstract
The effective representation and feature extraction of 3-D scenes from sparse and unstructured point clouds pose a significant challenge in 3-D object detection. In this article, we propose TransMRE, a network that enables fully sparse multiple observation plane feature fusion using LiDAR point clouds as single-modal input. TransMRE achieves this by sparsely factorizing a 3-D voxel scene into three separate observation planes: XY, XZ, and YZ planes. In addition, we propose Observation Plane Sparse Fusion and Interaction to explore the internal relationship between different observation planes. The Transformer mechanism is employed to realize feature attention within a single observation plane and feature attention across multiple observation planes. This recursive application of attention is done during multiple observation plane projection feature aggregation to effectively model the entire 3-D scene. This approach addresses the limitation of insufficient feature representation ability under a single bird’s-eye view (BEV) constructed by extremely sparse point clouds. Furthermore, TransMRE maintains the full sparsity property of the entire network, eliminating the need to convert sparse feature maps into dense feature maps. As a result, it can be effectively applied to LiDAR point cloud data with large scanning ranges, such as Argoverse 2, while ensuring low computational complexity. Extensive experiments were conducted to evaluate the effectiveness of TransMRE, achieving 64.9 mAP and 70.4 NDS on the nuScenes detection benchmark, and 32.3 mAP on the Argoverse 2 detection benchmark. These results demonstrate that our method outperforms state-of-the-art methods.
Ziming Zhu 朱梓铭
PhD. Loyal listener of Jay Chou.
A doctoral student of this laboratory, research interests include Artificial Intelligence, Autonomous Driving Environment Perception, 3D Object Detection and Semantic Occupancy Prediction.
Yu Zhu 朱煜
Professor. Experts in artificial intelligence and computer vision. Lab leader.
Leader of this laboratory, research interests include Artificial Intelligence, Computer Vision, Industrial controls, Digital Image and Video Processing, Machine learning, Deep Learning and Applications.
Kezhi Zhang 张可至
Master.
A master student of this laboratory, research interests include Artificial Intelligence, Computer Vision and Deep Learning.
Hangyu Li 李航宇
PhD. Super listener of 《三国恋》🎵.
A doctoral student of this laboratory, research interests include Neural Radiance Fields, Medical Image Processing and Generative Model.